Text Mining with transcripts of The Office

library(tidyverse)
library(tidytext)
theme_set(theme_light())In this post we are going to explore the transcripts of The Office using the tidytext package for text analysis by Julia Silge and David Robinson. Let’s start off by loading the data from the schrute package and taking a quick look at it.
#install.packages('schrute')
library(schrute)
office_df <- theoffice
glimpse(office_df)## Rows: 55,130
## Columns: 12
## $ index <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16…
## $ season <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ episode <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ episode_name <chr> "Pilot", "Pilot", "Pilot", "Pilot", "Pilot", "Pilot",…
## $ director <chr> "Ken Kwapis", "Ken Kwapis", "Ken Kwapis", "Ken Kwapis…
## $ writer <chr> "Ricky Gervais;Stephen Merchant;Greg Daniels", "Ricky…
## $ character <chr> "Michael", "Jim", "Michael", "Jim", "Michael", "Micha…
## $ text <chr> "All right Jim. Your quarterlies look very good. How …
## $ text_w_direction <chr> "All right Jim. Your quarterlies look very good. How …
## $ imdb_rating <dbl> 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6…
## $ total_votes <int> 3706, 3706, 3706, 3706, 3706, 3706, 3706, 3706, 3706,…
## $ air_date <fct> 2005-03-24, 2005-03-24, 2005-03-24, 2005-03-24, 2005-…office_df %>%
slice(1:3) %>%
knitr::kable()| index | season | episode | episode_name | director | writer | character | text | text_w_direction | imdb_rating | total_votes | air_date |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | Pilot | Ken Kwapis | Ricky Gervais;Stephen Merchant;Greg Daniels | Michael | All right Jim. Your quarterlies look very good. How are things at the library? | All right Jim. Your quarterlies look very good. How are things at the library? | 7.6 | 3706 | 2005-03-24 |
| 2 | 1 | 1 | Pilot | Ken Kwapis | Ricky Gervais;Stephen Merchant;Greg Daniels | Jim | Oh, I told you. I couldn’t close it. So… | Oh, I told you. I couldn’t close it. So… | 7.6 | 3706 | 2005-03-24 |
| 3 | 1 | 1 | Pilot | Ken Kwapis | Ricky Gervais;Stephen Merchant;Greg Daniels | Michael | So you’ve come to the master for guidance? Is this what you’re saying, grasshopper? | So you’ve come to the master for guidance? Is this what you’re saying, grasshopper? | 7.6 | 3706 | 2005-03-24 |
The data is in a tidy format where each column is a feature and each row an observation. The text column contains each characters’ lines for all nine seasons. It also contains the IMDB ratings for each episode. Let’s start off by visualizing the average ratings for each season.
office_df %>%
group_by(season) %>%
mutate(avgIMDB = mean(imdb_rating)) %>%
ggplot(aes(season, imdb_rating, group = season, fill = factor(season))) +
geom_boxplot() +
theme(legend.position = 'none') +
labs(title = "Average IMDB rading by season",
x = "Season",
y = "AVG IMDB rating") +
scale_x_continuous(breaks = 1:9)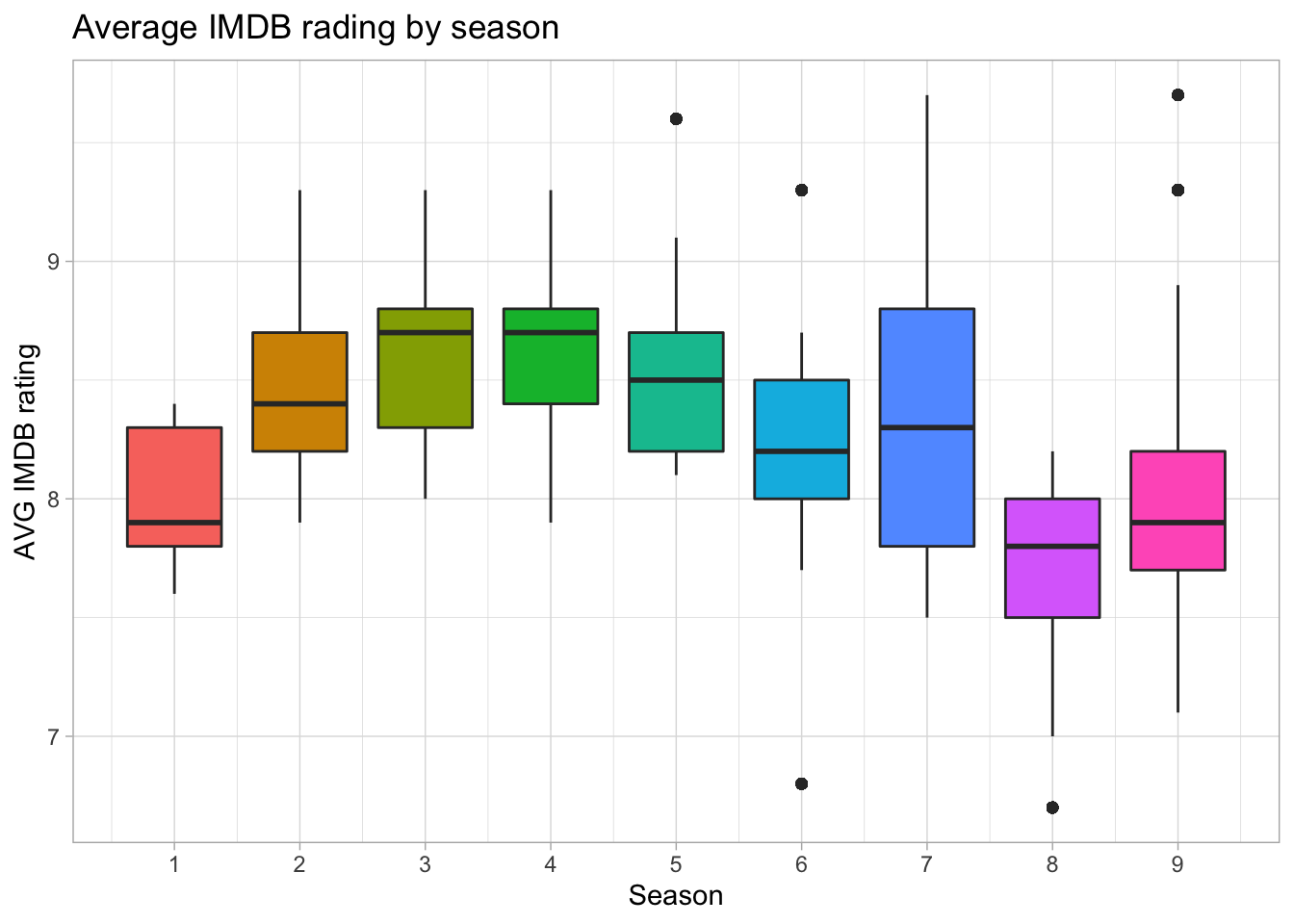
I have only watched a few episodes of The Office but I do know that Michael left in season 7. From the boxplots, we can see that the popularity peaks in season 3 and 4 and the popularity drops off in the last three seasons. Next, let’s consider the IMDB rating by episode.
office <- office_df %>%
select(season, episode, episode_name, imdb_rating, total_votes, air_date) %>%
mutate(air_date = as.Date(air_date)) %>%
distinct(., air_date, .keep_all = TRUE)
p <- office %>%
mutate(episode_num = row_number()) %>%
ggplot(aes(episode_num, imdb_rating, group = 1, color = factor(season))) +
geom_line() +
geom_smooth(se = FALSE) +
geom_point(aes(size = total_votes)) +
#geom_text(aes(label = episode_name), check_overlap = TRUE, hjust = 1) +
theme(legend.position = 'none') +
labs(title = 'Complete IMDB ratings for the office',
subtitle = 'point size ~ # of ratings',
x = 'Episode',
y = 'IMDB rating') +
ggplot2::aes(text = paste0('Episode name: ', episode_name,
'\nIMDB rating: ', imdb_rating,
'\ntotal votes: ', format(total_votes, big.mark = ','),
'\nseason: ', season)
)
plotly::ggplotly(p, tooltip = 'text')In the interactive plot above, we can see a more nuanced picture of episode ratings. The drop-off in popularity after Michael left is much more obvious.
For the NLP analysis, we will keep only the top 20 characters based on their respective line counts.
top_characters <- office_df %>%
count(character, sort = T) %>%
slice(1:20) %>%
mutate(character = fct_reorder(character, n))
top_characters %>%
ggplot(aes(n, character, fill = n)) +
geom_col() +
theme(legend.position = 'none')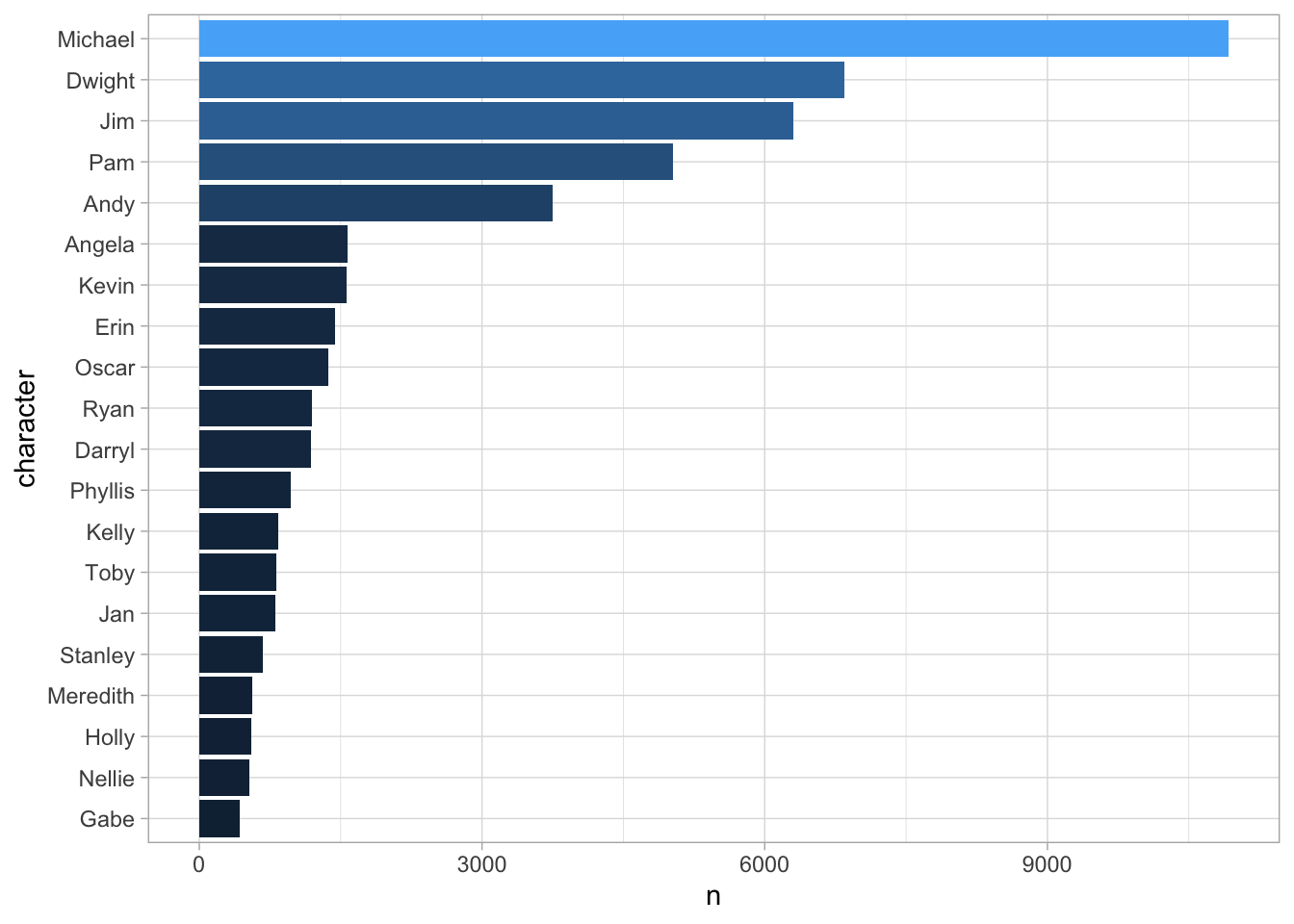
Now we are ready to explore the text. Let’s start off by using unnest_tokens(), the gateway function for NLP analysis with the tidytext package. Unnest_tokens converts lines of text into individual or multi-word tokens. We will start by converting the text so that every word is an observation. We will then use Ggplot2 to visualize the 8 most frequent word for each character. The tidytext package contains a data frame of stop words that can be used to filter out words that do not convey meaning, such as ‘the’, ‘and’, etc. I will also filter out character names and a few other words that were not included in the standard stop words.
junk_words <- c('yeah', 'hey', 'uh', 'um')
names_blacklist <- top_characters %>%
select(character) %>%
as.character()
words_df <- office_df %>%
unnest_tokens('word', 'text') %>%
inner_join(top_characters %>%
select(character), by = 'character') %>%
anti_join(stop_words, by = 'word') %>%
filter(!word %in% junk_words,
!word %in% names_blacklist) %>%
count(character, word) %>%
group_by(character) %>%
slice_max(n, n = 8)
words_df %>%
ungroup() %>%
slice_head(n=3) %>%
knitr::kable()| character | word | n |
|---|---|---|
| Andy | gonna | 130 |
| Andy | guys | 118 |
| Andy | time | 102 |
words_df %>%
mutate(word = reorder_within(word, n, character)) %>%
ggplot(aes(x = word, y = n, fill = character)) +
geom_col() +
scale_x_reordered() +
coord_flip() +
facet_wrap(~character, scales = "free") +
theme(legend.position = "none")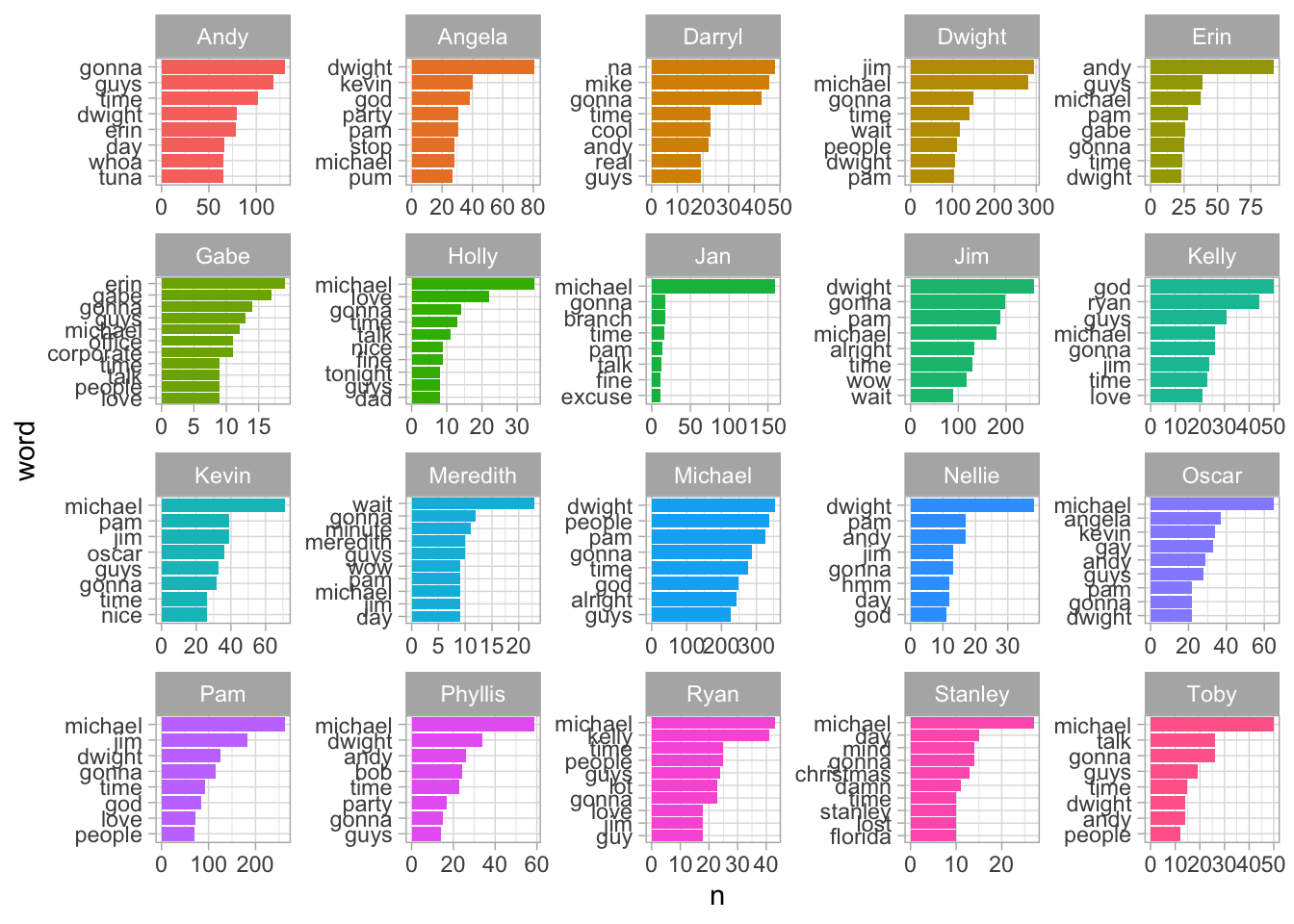
The function, bind_tf_idf() selects tokens that are unique to a character. According to Wikipedia, ‘Term frequency–inverse document frequency (TFIDF) is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus’. The description goes on to say that variations of TFIDF are commonly use to rank search engine query results.
words_df %>%
bind_tf_idf(word, character, n) %>%
group_by(character) %>%
top_n(tf_idf, n = 5) %>%
ungroup() %>%
ggplot(aes(x = reorder_within(word, tf_idf, character), y = tf_idf, fill = character)) +
geom_col() +
scale_x_reordered() +
coord_flip() +
facet_wrap(~character, scales = "free") +
theme(legend.position = "none") +
labs(x = "",
y = "TF-IDF of character-word pairs")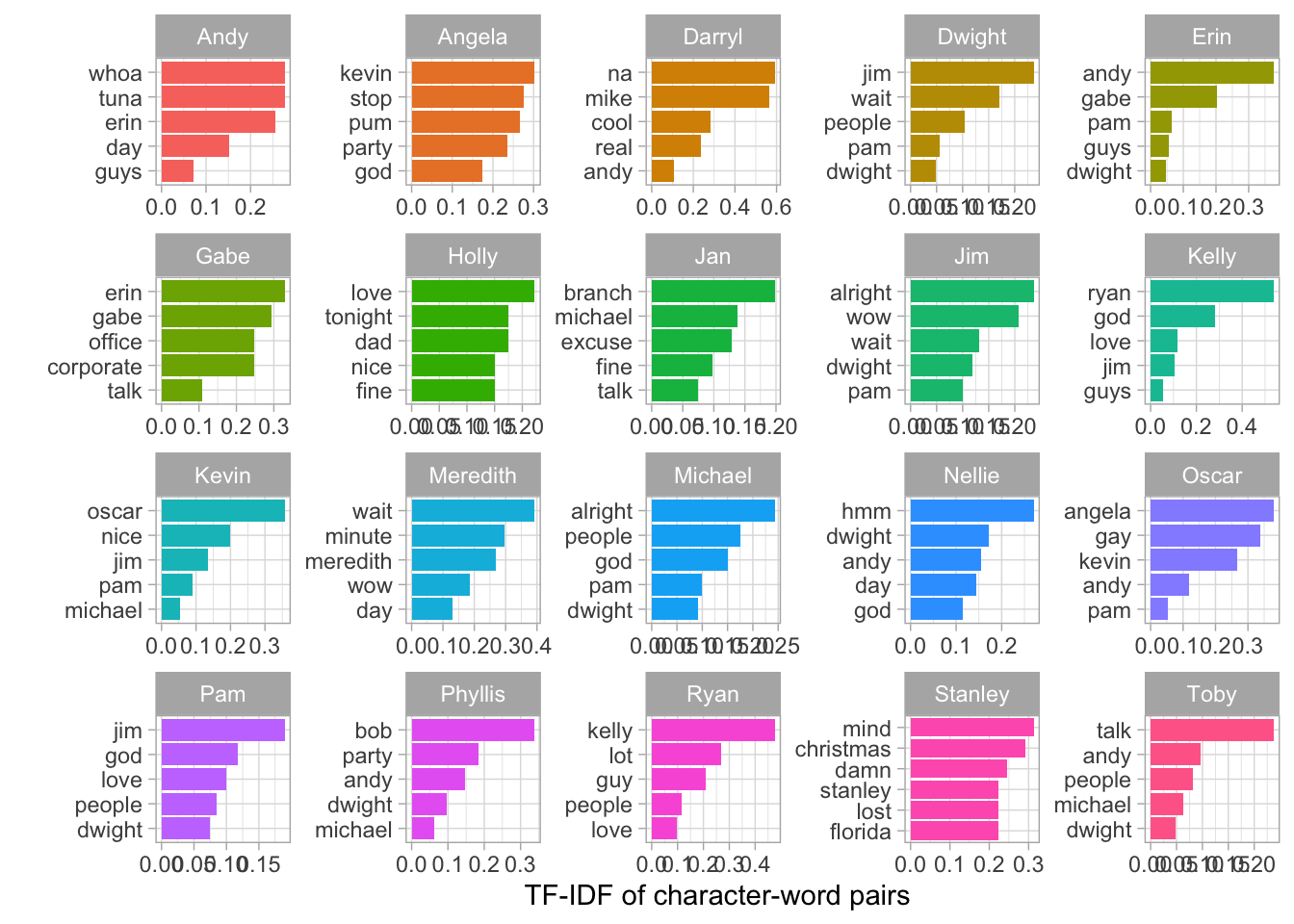
Sometimes a series of words in sequence might convey more meaning. The token number is referred to as n-grams. In the example below we will consider a tri-gram tokeniztion.
trigram_tokens <- office_df %>%
unnest_tokens('word', 'text', token = "ngrams", n = 3) %>%
inner_join(top_characters %>%
select(character), by = 'character') %>%
anti_join(stop_words, by = 'word') %>%
filter(!word %in% junk_words,
!word %in% names_blacklist) %>%
count(character, word) %>%
group_by(character) %>%
slice_max(n, n = 8)
trigram_tokens %>%
ungroup() %>%
slice_head(n=4) %>%
knitr::kable()| character | word | n |
|---|---|---|
| Andy | NA | 681 |
| Andy | i don’t know | 42 |
| Andy | no no no | 39 |
| Andy | you know what | 26 |
trigram_tokens %>%
bind_tf_idf(word, character, n) %>%
group_by(character) %>%
top_n(tf_idf, n = 5) %>%
ungroup() %>%
ggplot(aes(x = reorder_within(word, tf_idf, character), y = tf_idf, fill = character)) +
geom_col() +
scale_x_reordered() +
coord_flip() +
facet_wrap(~character, scales = "free") +
theme(legend.position = "none") +
labs(x = "",
y = "TF-IDF of character-word pairs")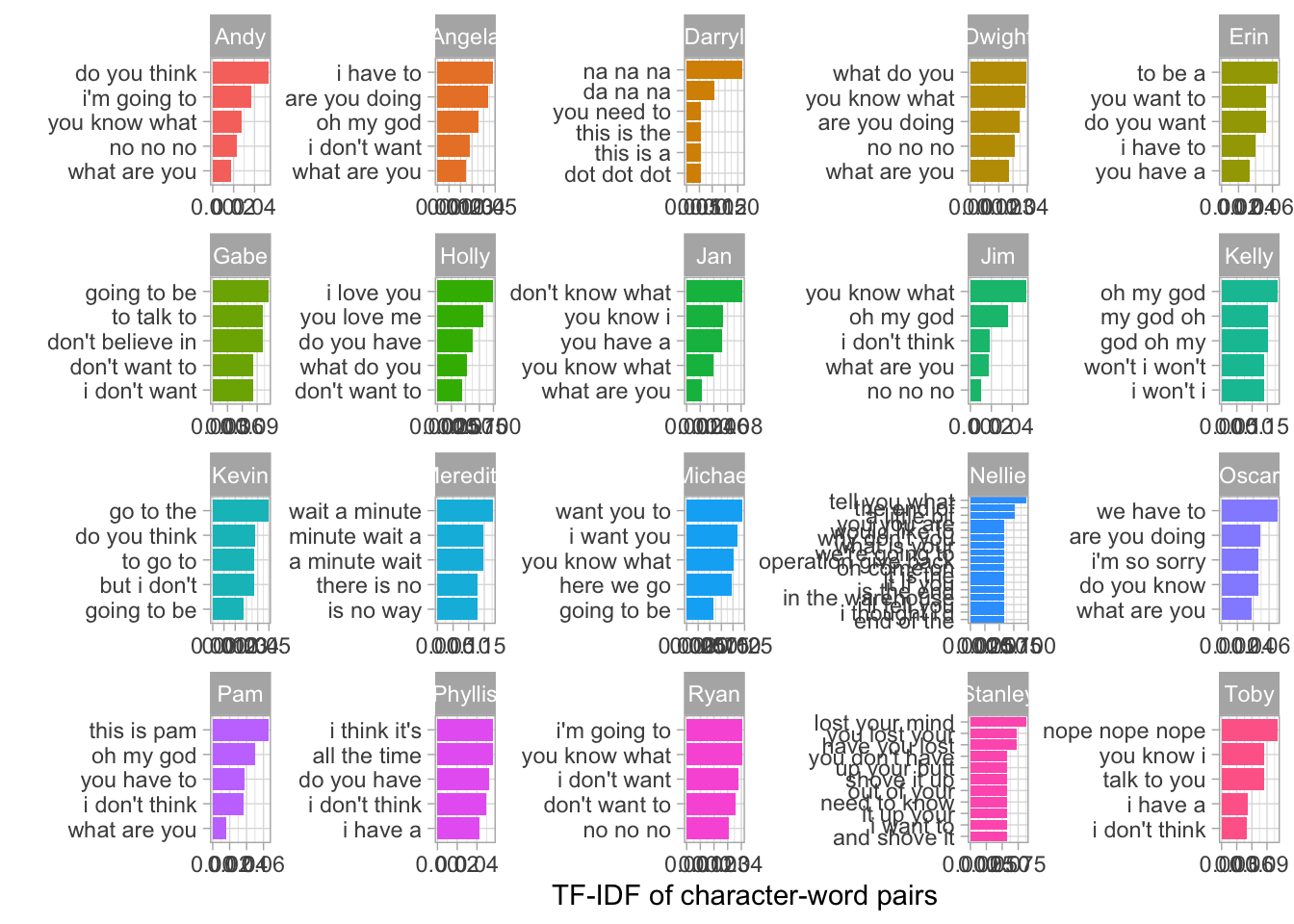
The overall sentiment of The Office can be interpretted using the get_sentiments() function. In this example, we are using the bing lexicon to compare positive and negative sentiment over all 9 seasons of the show.
office_df %>%
unnest_tokens('word', 'text') %>%
inner_join(top_characters %>%
select(character), by = 'character') %>%
anti_join(stop_words, by = 'word') %>%
filter(!word %in% junk_words,
!word %in% names_blacklist) %>%
select(season, word) %>%
inner_join(get_sentiments(lexicon = "bing")) %>%
group_by(season) %>%
count(sentiment) %>%
ungroup() %>%
ggplot(aes(x = season, y = n, fill = sentiment, group = sentiment)) +
geom_area() +
scale_x_continuous(breaks = 1:9) +
labs(title = 'Area plot of positive and negative sentiments over seasons') 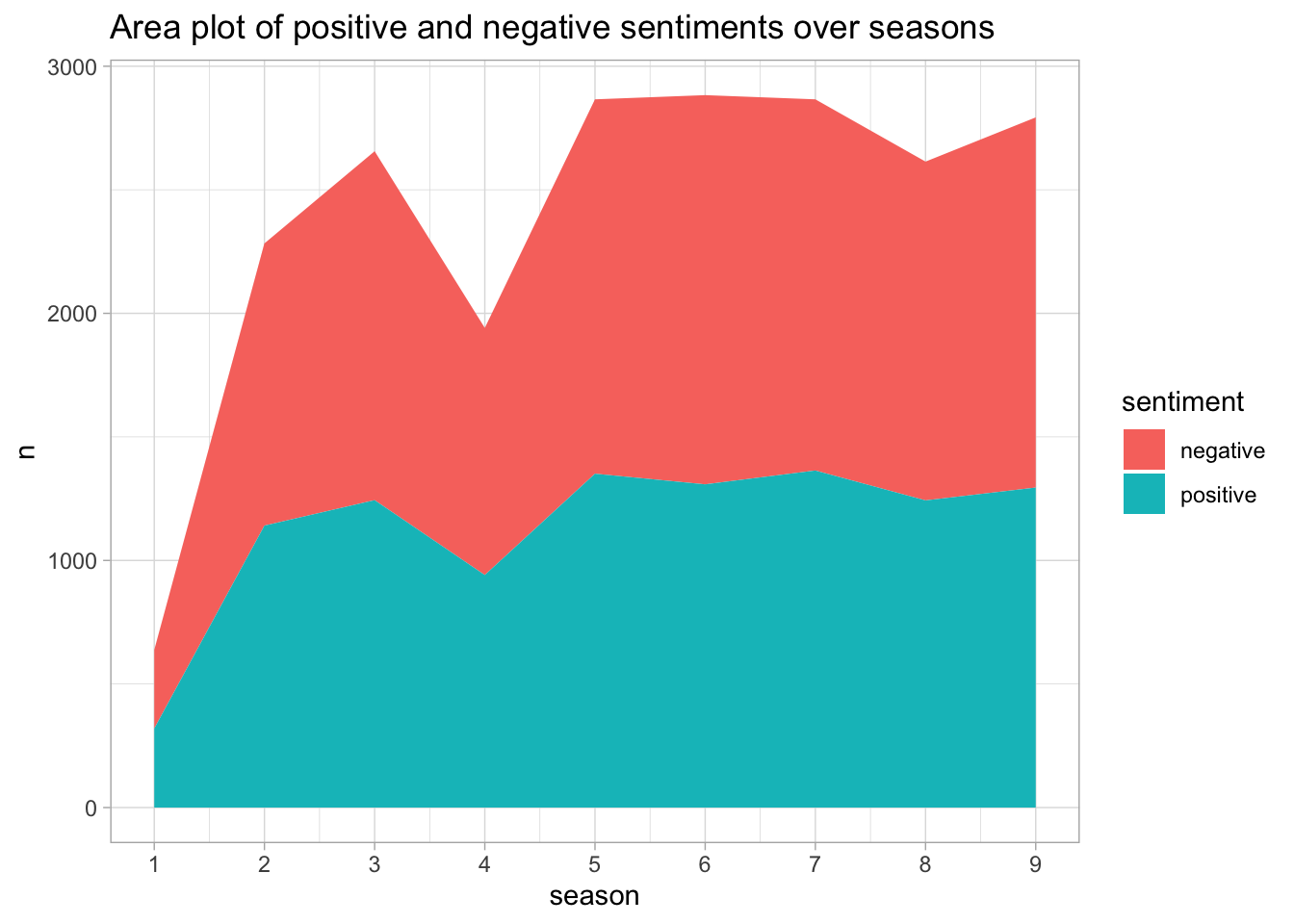
One last quick visual that we might want to summon is the wordcloud. Wordclouds use font size to emphasize the frequency of each word in the document. In the examples below, I will consider a general word cloud, as well as look specific examples based on individual characters.
library(RColorBrewer)
library(wordcloud)
pal <- brewer.pal(8,"Dark2")
words_expanded <- office_df %>%
unnest_tokens('word', 'text') %>%
inner_join(top_characters %>%
select(character), by = 'character') %>%
anti_join(stop_words, by = 'word') %>%
filter(!word %in% junk_words,
!word %in% names_blacklist) %>%
count(character, word) %>%
group_by(character) %>%
slice_max(n, n = 50)Most words in The Office
words_expanded %>%
ungroup() %>%
with(wordcloud(word, n, random.order = FALSE, max.words = 50, colors=pal))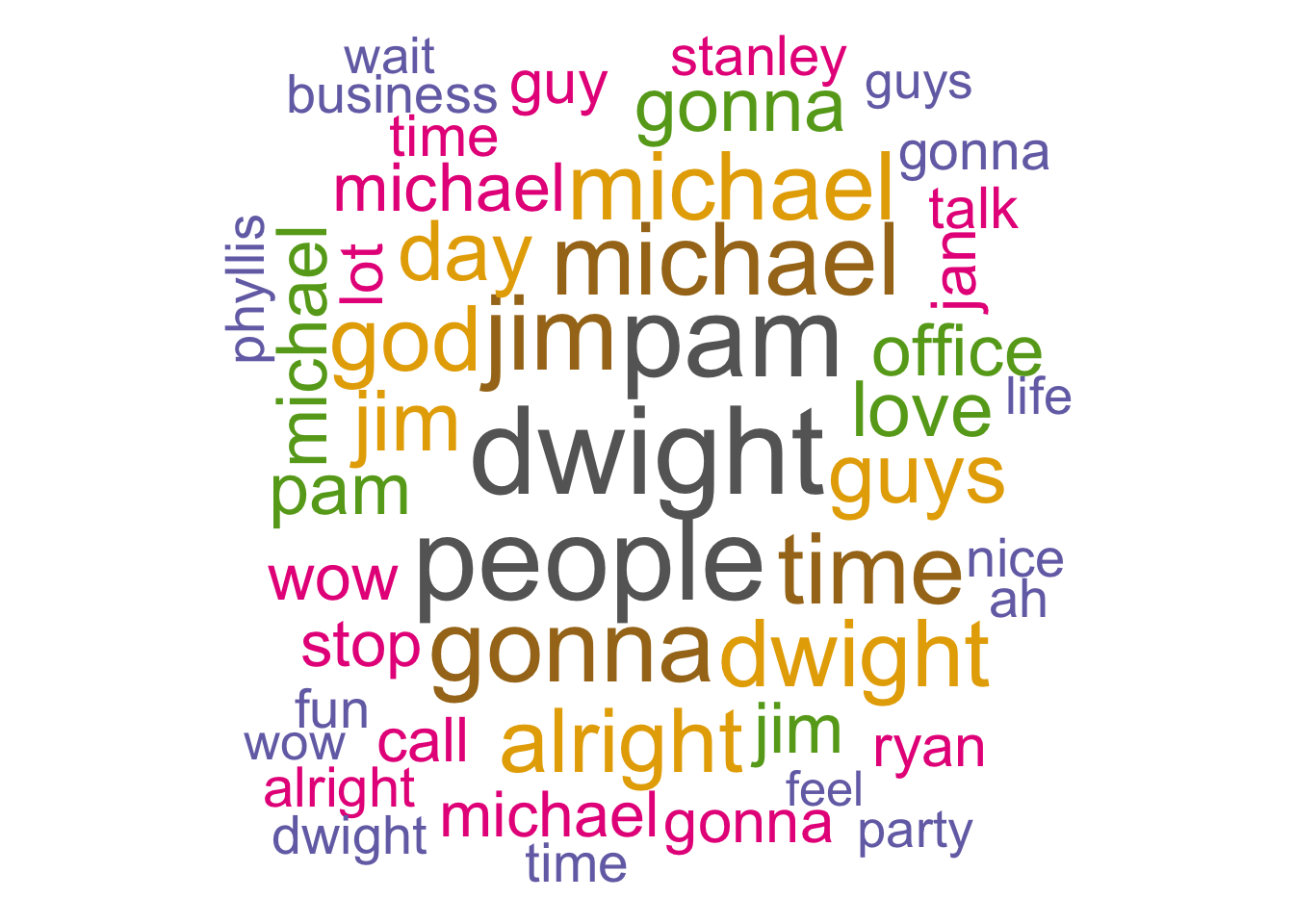
Most common words for Jim
words_expanded %>%
ungroup() %>%
filter(character == "Jim") %>%
with(wordcloud(word, n, random.order = FALSE, max.words = 50, colors=pal))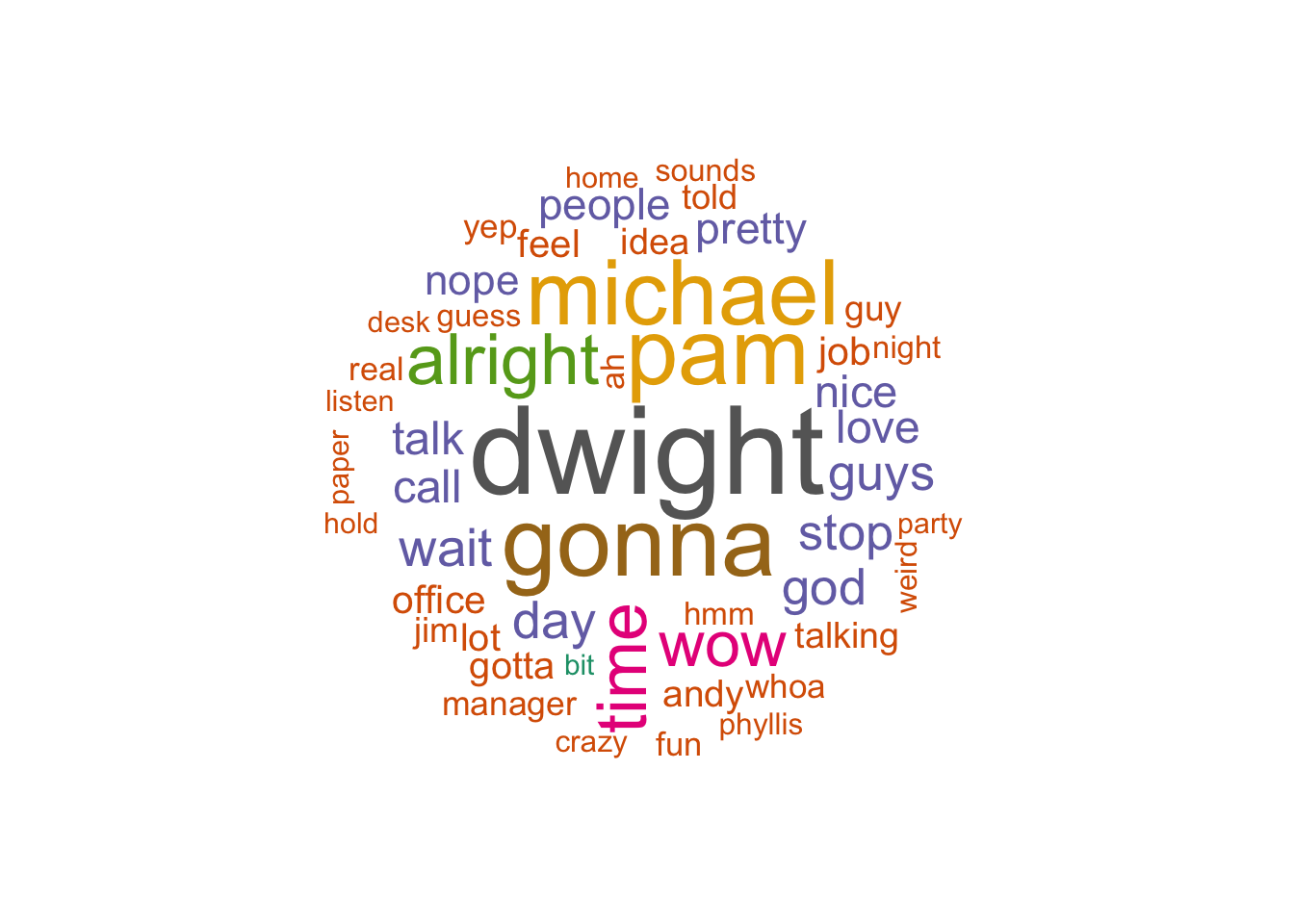
Most common words for Pam
words_expanded %>%
ungroup() %>%
filter(character == "Pam") %>%
with(wordcloud(word, n, random.order = FALSE, max.words = 50, colors=pal))
This post was a lot of fun to work on and I hope to do more NLP analysis in the future. NLP provides a powerful way to condense large amounts of text data into easily interpretable insights. The Tidytext package is a great way to work with text and complements the Tidyverse ecosystem.
Gabriel Mednick, PhD
Data scientist, biochemist, computational biologist, educator, life enthusiast