Iris Classification

Iris data
The iris dataset is a classic, so much so that it’s included in the datasets package that comes with every installation of R. You can use data() to see a list of all available datasets. Datasets that are associated with packages can be found in a similar way, e.g., data(package = 'dplyr').
Let’s take a look at the data.
# load the iris data set and clean the column names with janitor::clean_names()
iris_df<- iris %>%
clean_names()
iris_df %>% head()## sepal_length sepal_width petal_length petal_width species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosairis_df %>% count(species)## species n
## 1 setosa 50
## 2 versicolor 50
## 3 virginica 50# equal number of each species, 150 total
iris_df %>% str()## 'data.frame': 150 obs. of 5 variables:
## $ sepal_length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ sepal_width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ petal_length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ petal_width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...The dataset contains three unique species of iris and four variables or features (sepal length and width, and petal length and width). The data is clean but with only 150 observations it’s a wee bit small for training a model. To compensate for this, we will use bootstrap resampling.
Outline
Train a classification model to predict flower species based on the four available features
The model formula will have the form species ~ . where . represents all explanatory variables in the data.
Visualize relationships
Before we do any kind of machine learning, it’s helpful to visualize the data and develop a better understanding of the variables as well as their relationships. This will also give us a stronger intuitive sense about the potential predictive power of the data.
library(ggforce)
sepal <- iris_df %>%
ggplot(aes(sepal_length, sepal_width, color = species)) +
geom_point(size = 1) +
facet_wrap(~species) +
labs(x = 'sepal length',
y = 'sepal width') +
theme(legend.position = 'none')
petal <- iris_df %>%
ggplot(aes(petal_length, petal_width, color = species)) +
geom_point(size =1) +
facet_wrap(~species) +
labs(x = 'petal length',
y = 'petal width') +
theme(legend.position = 'none')
(petal/sepal) # patchwork allows us to arrange plots side-by-side or stacked 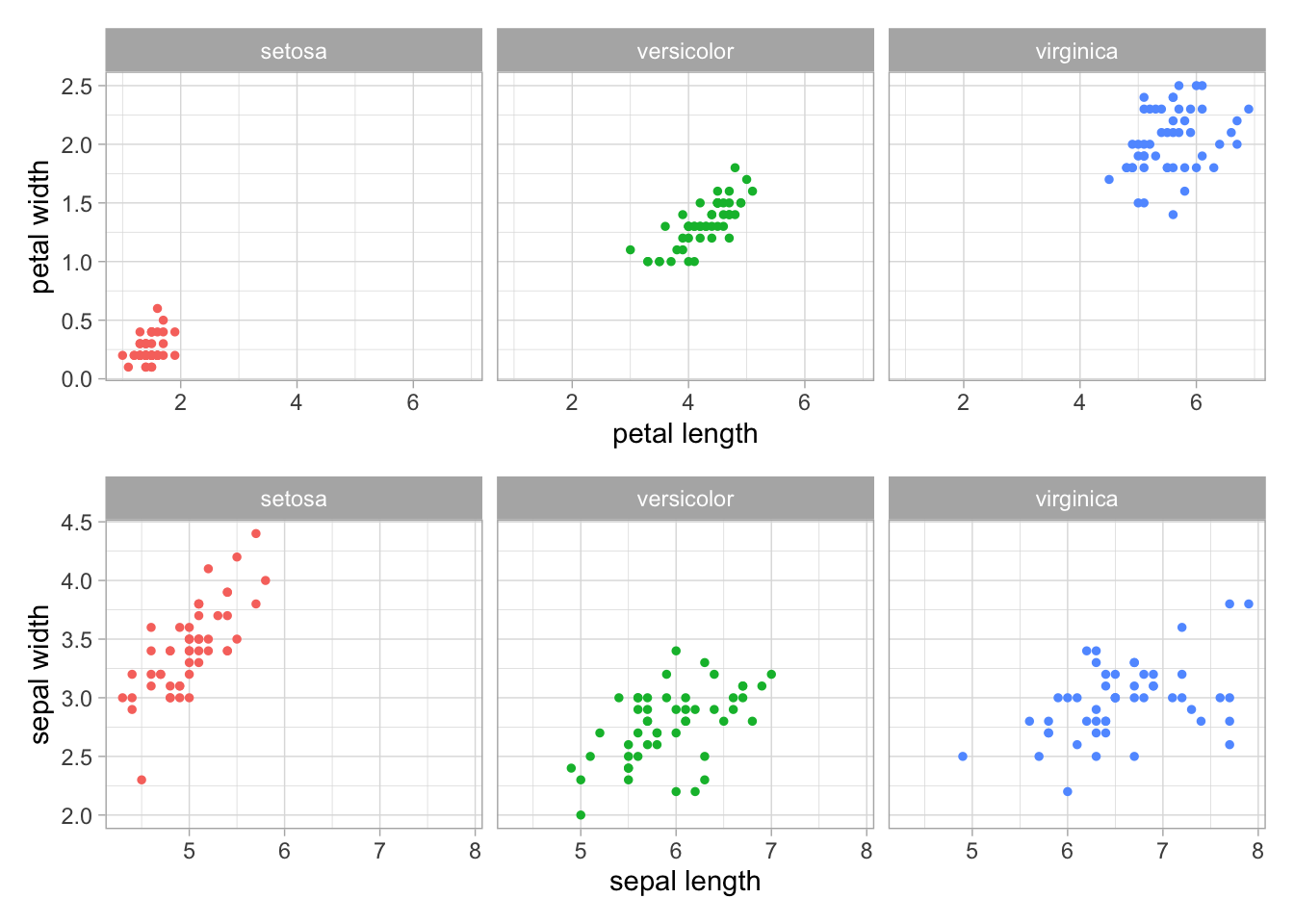
sl_sw <- iris_df %>%
ggplot(aes(sepal_length, sepal_width, color = species)) +
geom_point(size = 1) +
labs(x = 'sepal length',
y = 'sepal width') +
theme(legend.position = 'none')
sl_sw +
geom_mark_hull(
aes(fill = NULL, label = species),
concavity = 2) +
labs(title = "Comparing sepal length vs sepal width across species")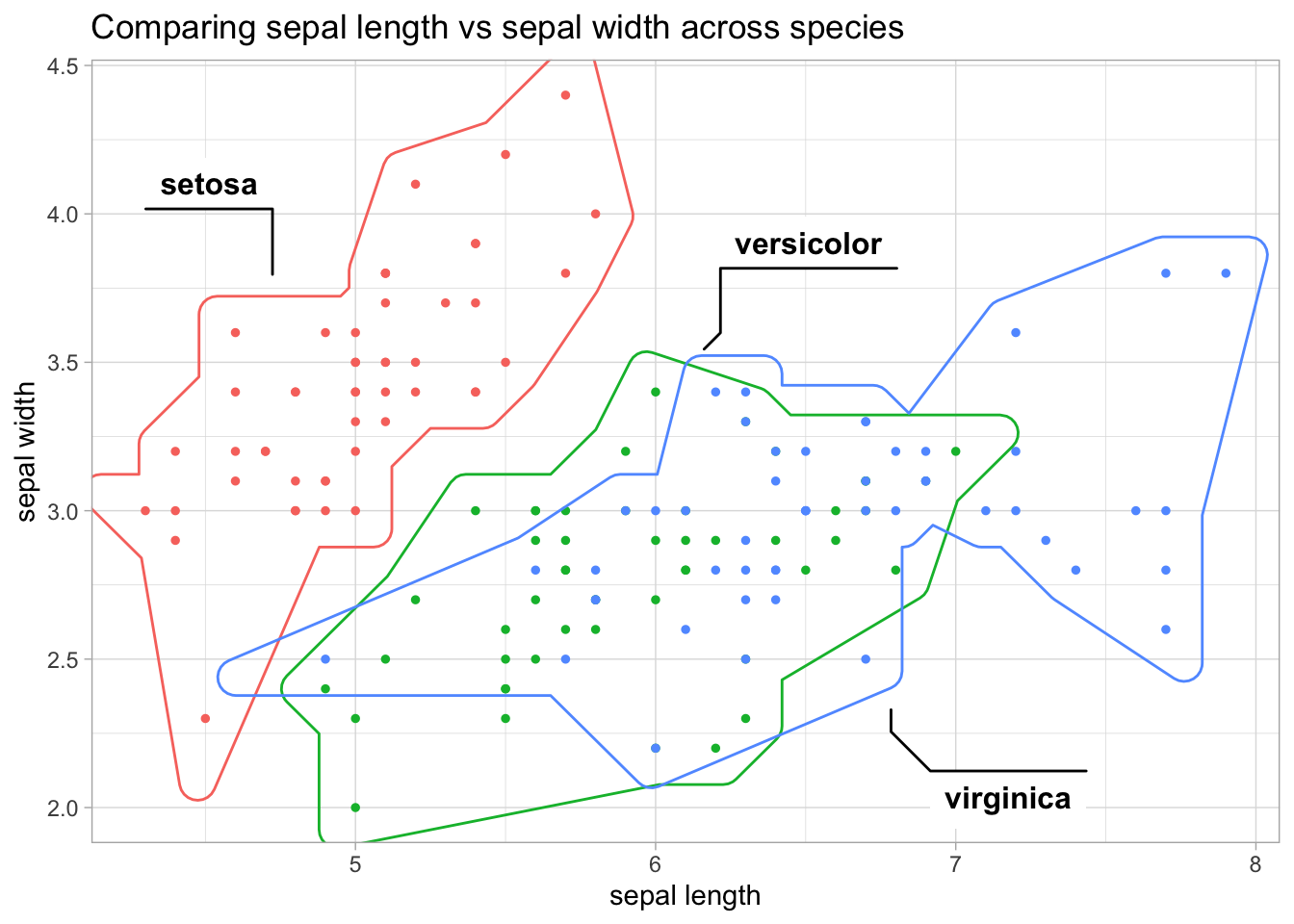
pl_pw <- iris_df %>%
ggplot(aes(petal_length, petal_width, color = species)) +
geom_point(size =1) +
labs(x = 'petal length',
y = 'petal width') +
theme(legend.position = 'none')
pl_pw +
geom_mark_hull(
aes(fill = NULL, label = species),
concavity = 2) +
labs(title = "Comparing petal length vs petal width across species")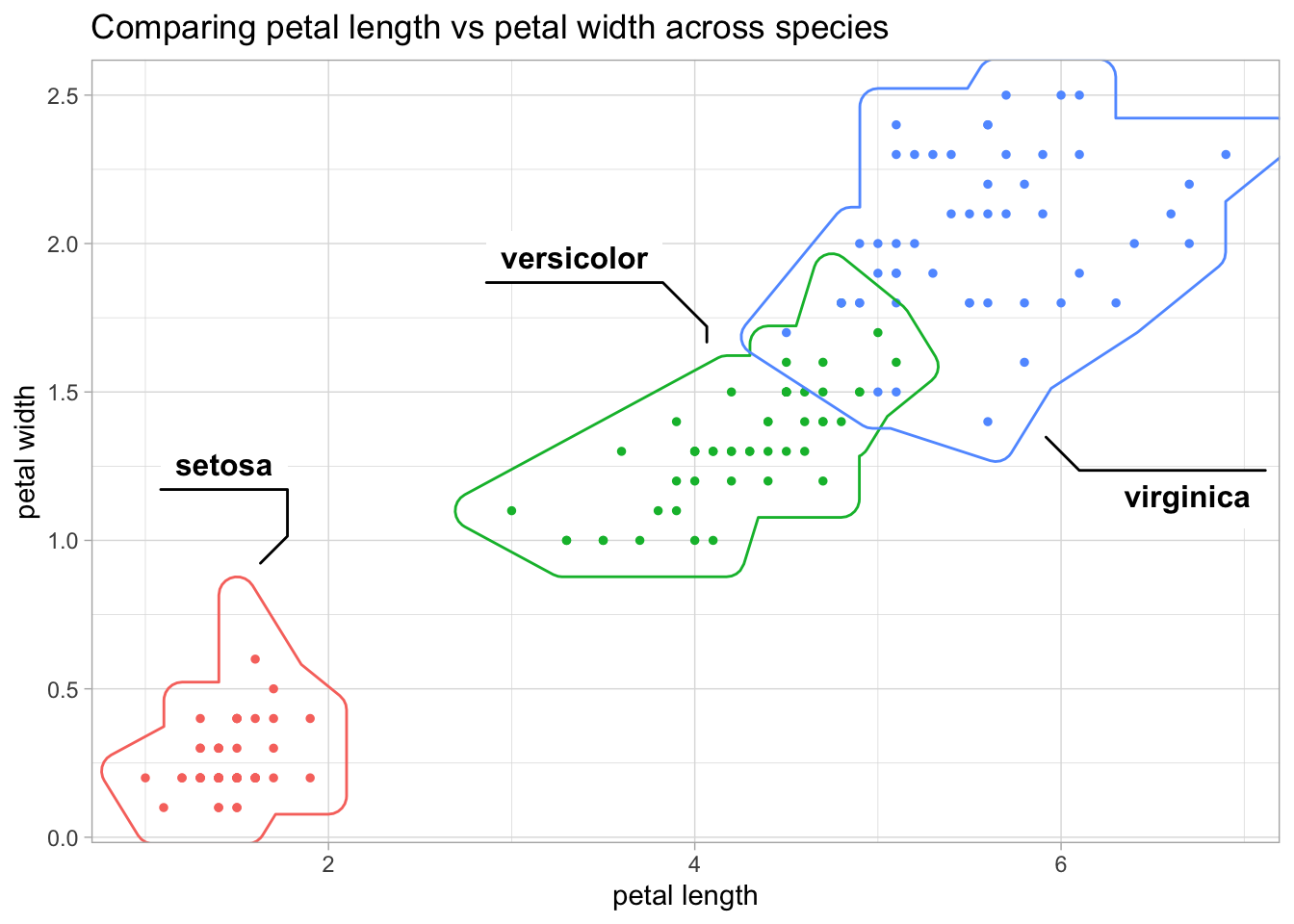
Let’s change the shape of our data by combining the four iris features into a single column (metric) and the associated values will populate a new column (value). This transformation into a longer dataset can be achieved with the function pivot_longer().
iris_df_long <- iris_df %>%
pivot_longer(cols = sepal_length:petal_width,
names_to = 'metric',
values_to ='value')
# A boxplot is a great way to compare the distribution of each features by species.
iris_df_long %>%
ggplot(aes(species, value, fill = species)) +
geom_boxplot(alpha = 0.3) +
facet_wrap(~ metric, scales = "free_y")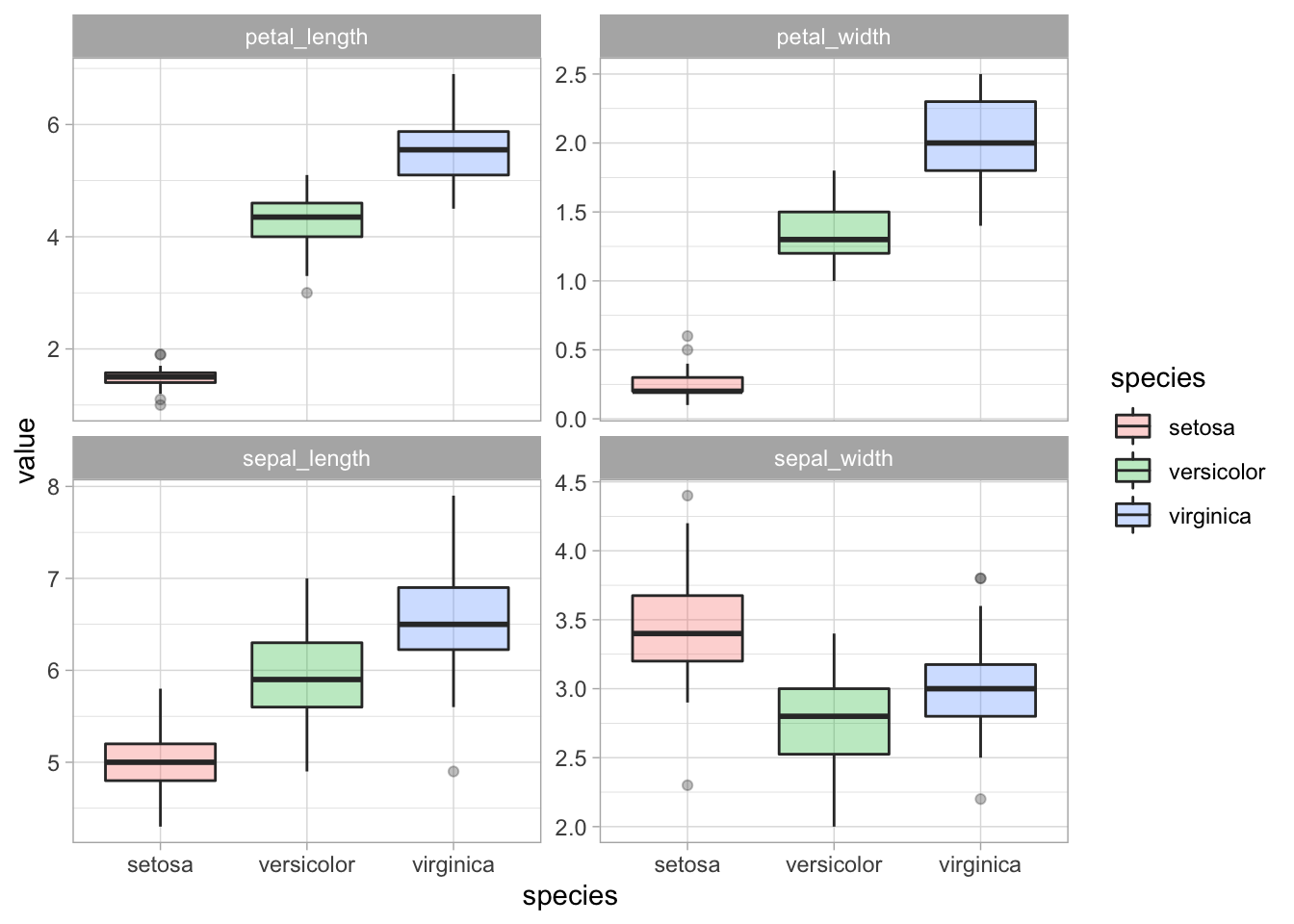
# Looking at the data in a different way, geom_density is a nice alternative to geom_histogram.
iris_df_long %>%
ggplot(aes(value, fill = species)) +
geom_density(alpha = .5) +
facet_wrap(~ metric, scales = "free")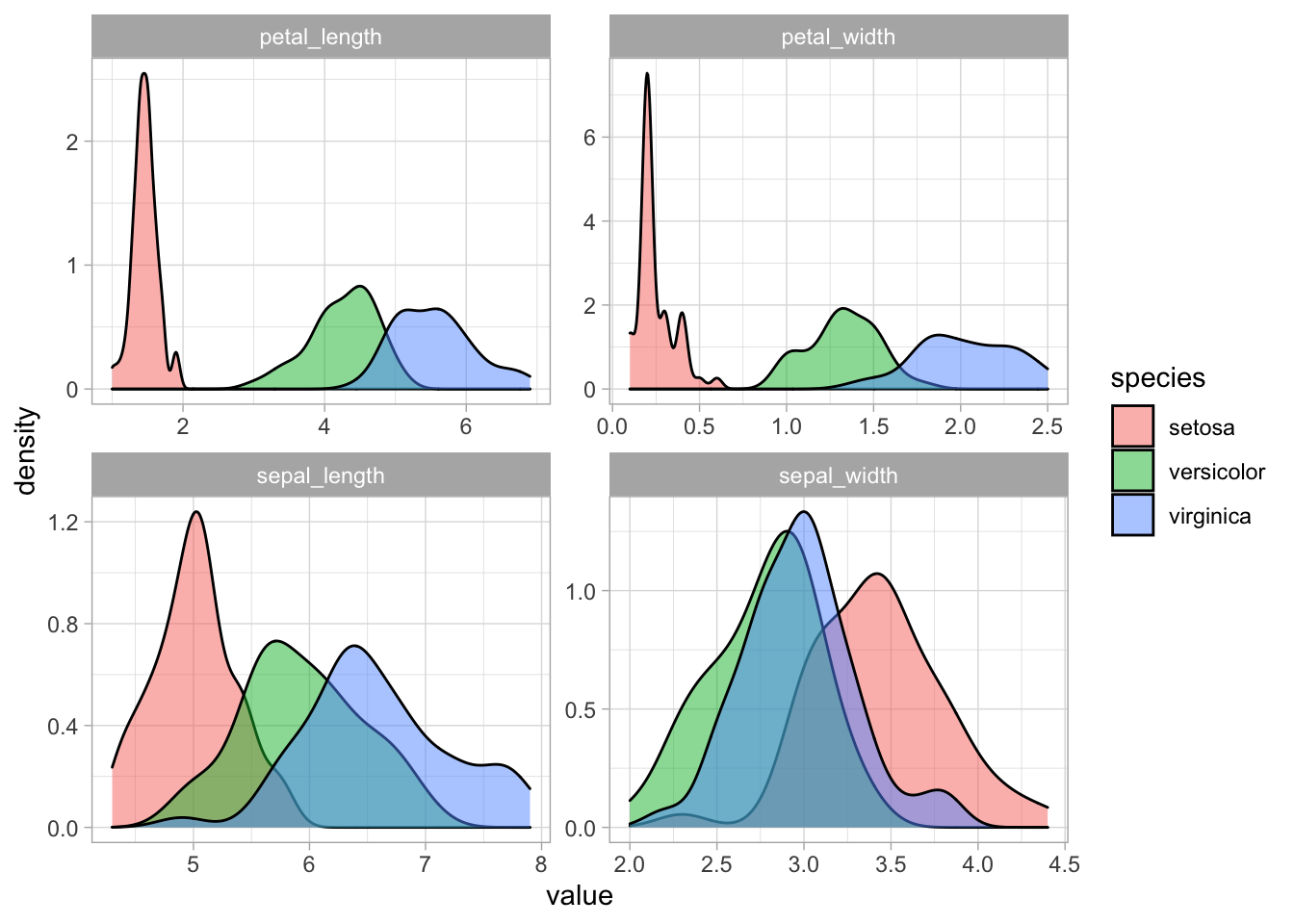
Splitting the data into training and test sets
By default, initial split() provides a 75:25 split for our train and test sets respectively. Since our dataset is small to begin with, we are going to make bootstrap resamples from the training data. The function bootstraps() will split the data into training and test sets, then repeat this process with replacement a specified number of times (25 is the default).
set.seed(123)
tidy_split <- initial_split(iris_df)
tidy_split## <Analysis/Assess/Total>
## <112/38/150>iris_train <- training(tidy_split)
iris_test <- testing(tidy_split)
iris_boots <- bootstraps(iris_train, times = 30)
iris_boots## # Bootstrap sampling
## # A tibble: 30 × 2
## splits id
## <list> <chr>
## 1 <split [112/45]> Bootstrap01
## 2 <split [112/43]> Bootstrap02
## 3 <split [112/39]> Bootstrap03
## 4 <split [112/40]> Bootstrap04
## 5 <split [112/39]> Bootstrap05
## 6 <split [112/41]> Bootstrap06
## 7 <split [112/35]> Bootstrap07
## 8 <split [112/37]> Bootstrap08
## 9 <split [112/42]> Bootstrap09
## 10 <split [112/37]> Bootstrap10
## # … with 20 more rowsRecipes
Recipes is a powerful tool with functions for a wide range of feature engineering tasks designed to prepare data for modeling. Typing recipes:: into the Rstudio console is a great way to browse the available functions in the package.

Let’s create a simple recipe to demonstrate optional feature engineering steps for our numeric data.
iris_rec <- recipe(species ~., data = iris_train) %>%
step_pca(all_predictors()) %>%
step_normalize(all_predictors())
prep <- prep(iris_rec)
kable(head(iris_juice <- juice(prep)))| species | PC1 | PC2 | PC3 | PC4 |
|---|---|---|---|---|
| setosa | 1.7227690 | 1.2539796 | -0.0911528 | -0.1704339 |
| setosa | 1.2188957 | 1.3368015 | -0.3665258 | 0.1981136 |
| virginica | -2.0712468 | -1.0080369 | 0.9961660 | -1.8706481 |
| setosa | 1.5543285 | 1.2288655 | 0.4323305 | -0.4811825 |
| virginica | -0.4876555 | -0.7920225 | 1.1713477 | -0.9553358 |
| virginica | -0.8207125 | -0.7696463 | 0.5013655 | 0.8697351 |
Creating models with Parsnip
Let’s set up two different models: first, a generalized linear model or glmnet. In this step we will create the model, workflow and fit the bootstraps. Let’s take a look at the output from each step.
# set seed
set.seed(1234)
# generate the glmnet model with parsnip
glmnet_mod <- multinom_reg(penalty = 0) %>%
set_engine("glmnet") %>%
set_mode("classification")
glmnet_mod## Multinomial Regression Model Specification (classification)
##
## Main Arguments:
## penalty = 0
##
## Computational engine: glmnet# create a workflow
glmnet_wf <- workflow() %>%
add_formula(species ~ .)
glmnet_wf## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Formula
## Model: None
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## species ~ .# add the model to the workflow and use iris_boots to fit our model 25 times
glmnet_results <- glmnet_wf %>%
add_model(glmnet_mod) %>%
fit_resamples(
resamples = iris_boots,
control = control_resamples(extract = extract_model,
save_pred = TRUE)
)
glmnet_results## # Resampling results
## # Bootstrap sampling
## # A tibble: 30 × 6
## splits id .metrics .notes .extracts .predictions
## <list> <chr> <list> <list> <list> <list>
## 1 <split [112/45]> Bootstrap01 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [45…
## 2 <split [112/43]> Bootstrap02 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [43…
## 3 <split [112/39]> Bootstrap03 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [39…
## 4 <split [112/40]> Bootstrap04 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [40…
## 5 <split [112/39]> Bootstrap05 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [39…
## 6 <split [112/41]> Bootstrap06 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [41…
## 7 <split [112/35]> Bootstrap07 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [35…
## 8 <split [112/37]> Bootstrap08 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [37…
## 9 <split [112/42]> Bootstrap09 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [42…
## 10 <split [112/37]> Bootstrap10 <tibble [2 × 4]> <tibbl… <tibble [… <tibble [37…
## # … with 20 more rows# look at the model metrics
collect_metrics(glmnet_results)## # A tibble: 2 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy multiclass 0.958 30 0.00507 Preprocessor1_Model1
## 2 roc_auc hand_till 0.994 30 0.00119 Preprocessor1_Model1Now for a random forest model. We only need to change a few things and walah!
set.seed(1234)
rf_mod <- rand_forest() %>%
set_engine("ranger") %>%
set_mode("classification")
# We set up a workflow and add the parts of our model together like legos
rf_wf <- workflow() %>%
add_formula(species ~ .)
# Here we fit our 25 resampled datasets
rf_results <- rf_wf %>%
add_model(rf_mod) %>%
fit_resamples(
resamples = iris_boots,
control = control_resamples(save_pred = TRUE)
)
collect_metrics(rf_results)## # A tibble: 2 × 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy multiclass 0.953 30 0.00449 Preprocessor1_Model1
## 2 roc_auc hand_till 0.995 30 0.000800 Preprocessor1_Model1Here’s a look at the confusion matrix summaries for both models. The confusion matrix let’s us see the correct and incorrect predictions of our models in a single table.
glmnet_results %>%
conf_mat_resampled() ## # A tibble: 9 × 3
## Prediction Truth Freq
## <fct> <fct> <dbl>
## 1 setosa setosa 14
## 2 setosa versicolor 0
## 3 setosa virginica 0
## 4 versicolor setosa 0
## 5 versicolor versicolor 10.2
## 6 versicolor virginica 0.833
## 7 virginica setosa 0
## 8 virginica versicolor 0.867
## 9 virginica virginica 14.2rf_results %>%
conf_mat_resampled() ## # A tibble: 9 × 3
## Prediction Truth Freq
## <fct> <fct> <dbl>
## 1 setosa setosa 14
## 2 setosa versicolor 0
## 3 setosa virginica 0
## 4 versicolor setosa 0
## 5 versicolor versicolor 10.2
## 6 versicolor virginica 1.03
## 7 virginica setosa 0
## 8 virginica versicolor 0.867
## 9 virginica virginica 14The ROC curve helps us visually interpret our model performance at every threshold.
glmnet_results %>%
collect_predictions() %>%
group_by(id) %>%
roc_curve(species, .pred_setosa:.pred_virginica) %>%
autoplot()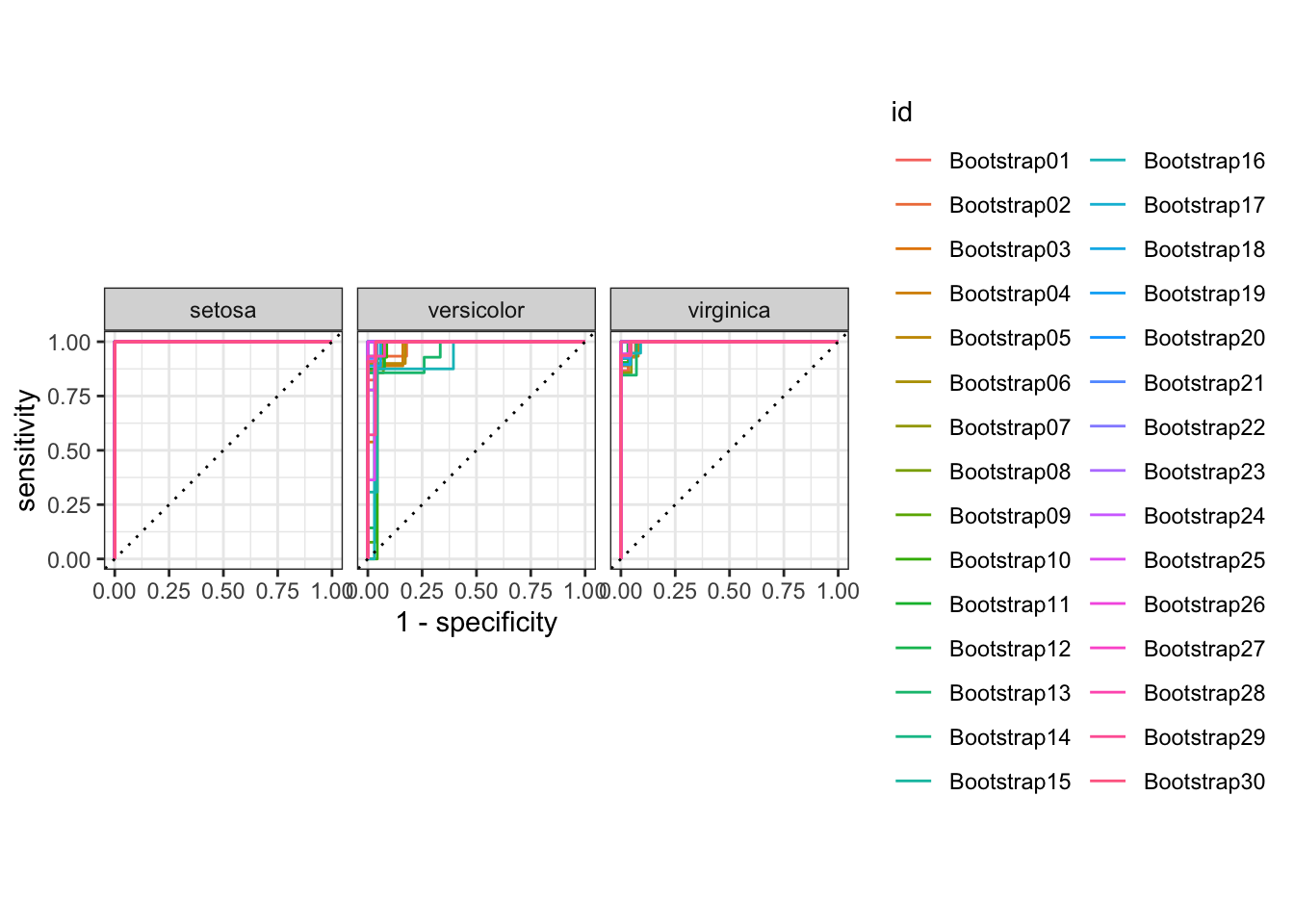
rf_results %>%
collect_predictions() %>%
group_by(id) %>%
roc_curve(species, .pred_setosa:.pred_virginica) %>%
autoplot() +
theme(legend.position = 'none')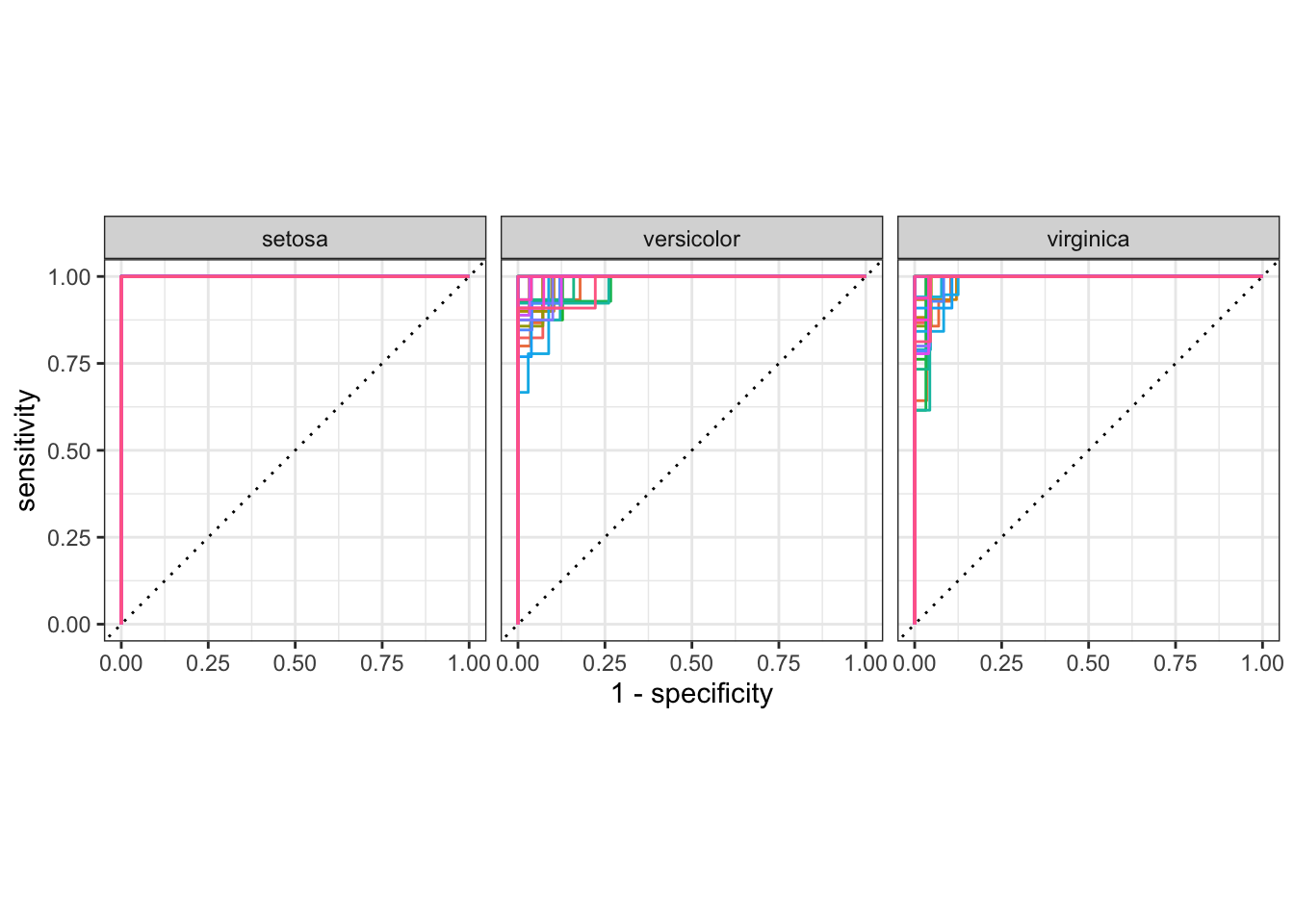
Final fit
By using the last_fit(tidy_split), we are able to train our model on the training set and test the model on the testing set in one fell swoop! Note, this is the only time we use the test set.
final_glmnet <- glmnet_wf %>%
add_model(glmnet_mod) %>%
last_fit(tidy_split)
final_glmnet## # Resampling results
## # Manual resampling
## # A tibble: 1 × 6
## splits id .metrics .notes .predictions .workflow
## <list> <chr> <list> <list> <list> <list>
## 1 <split [112/38]> train/test split <tibble [… <tibble … <tibble [38 … <workflo…final_rf <- rf_wf %>%
add_model(rf_mod) %>%
last_fit(tidy_split)
final_rf## # Resampling results
## # Manual resampling
## # A tibble: 1 × 6
## splits id .metrics .notes .predictions .workflow
## <list> <chr> <list> <list> <list> <list>
## 1 <split [112/38]> train/test split <tibble [… <tibble … <tibble [38 … <workflo…Confusion Matrices
Finally, let’s generate a multiclass confusion matrix with the results from our test data. The confusion matrix provides a count of each outcome for all possible outcomes. The columns contain the true values and the predictions are assigned to the rows.
collect_metrics(final_glmnet)## # A tibble: 2 × 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 accuracy multiclass 0.974 Preprocessor1_Model1
## 2 roc_auc hand_till 0.991 Preprocessor1_Model1collect_predictions(final_glmnet) %>%
conf_mat(species, .pred_class) %>%
autoplot(type = 'heatmap') 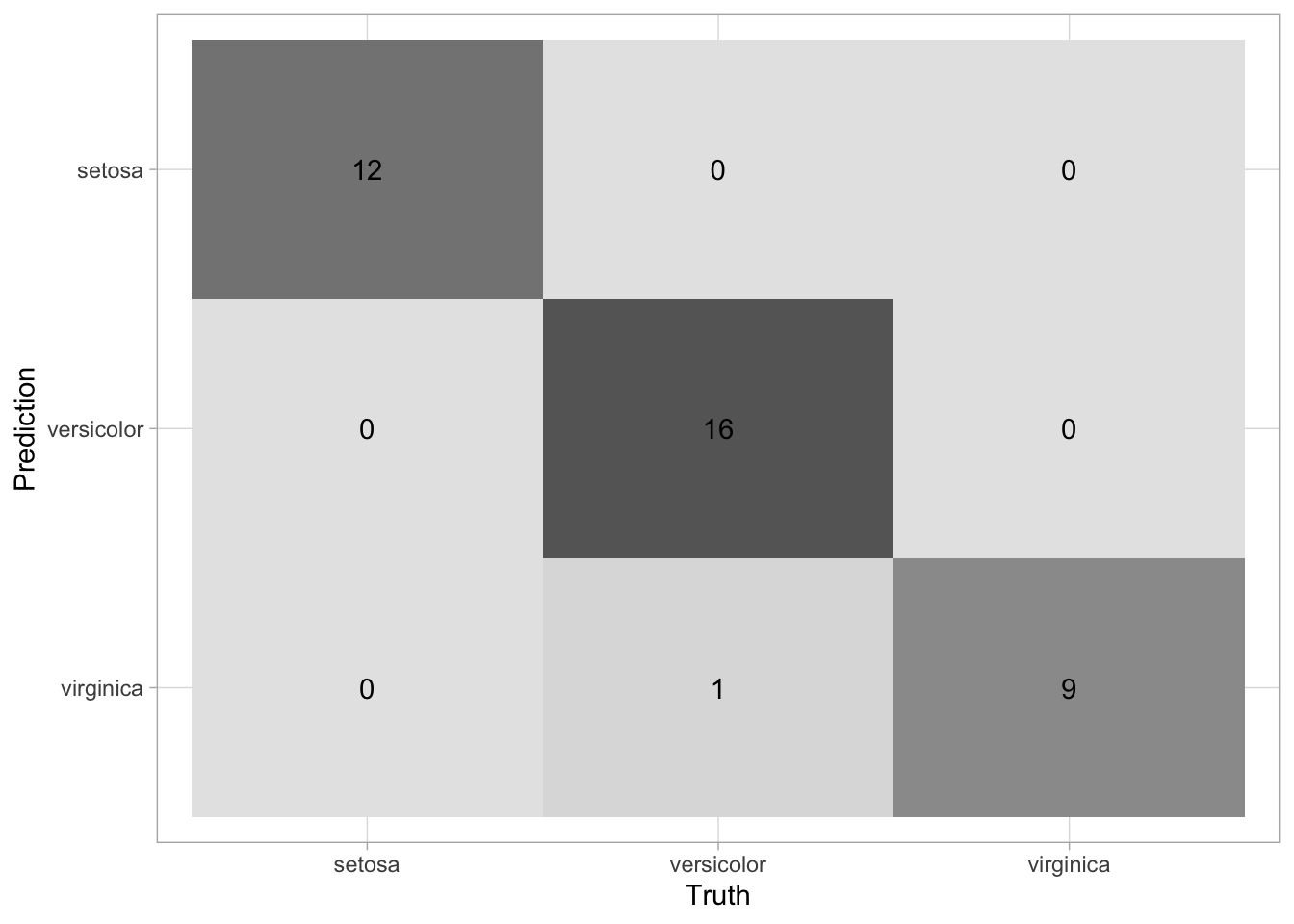
collect_metrics(final_rf)## # A tibble: 2 × 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 accuracy multiclass 0.974 Preprocessor1_Model1
## 2 roc_auc hand_till 0.998 Preprocessor1_Model1collect_predictions(final_rf) %>%
conf_mat(species, .pred_class) %>%
autoplot(type = 'heatmap')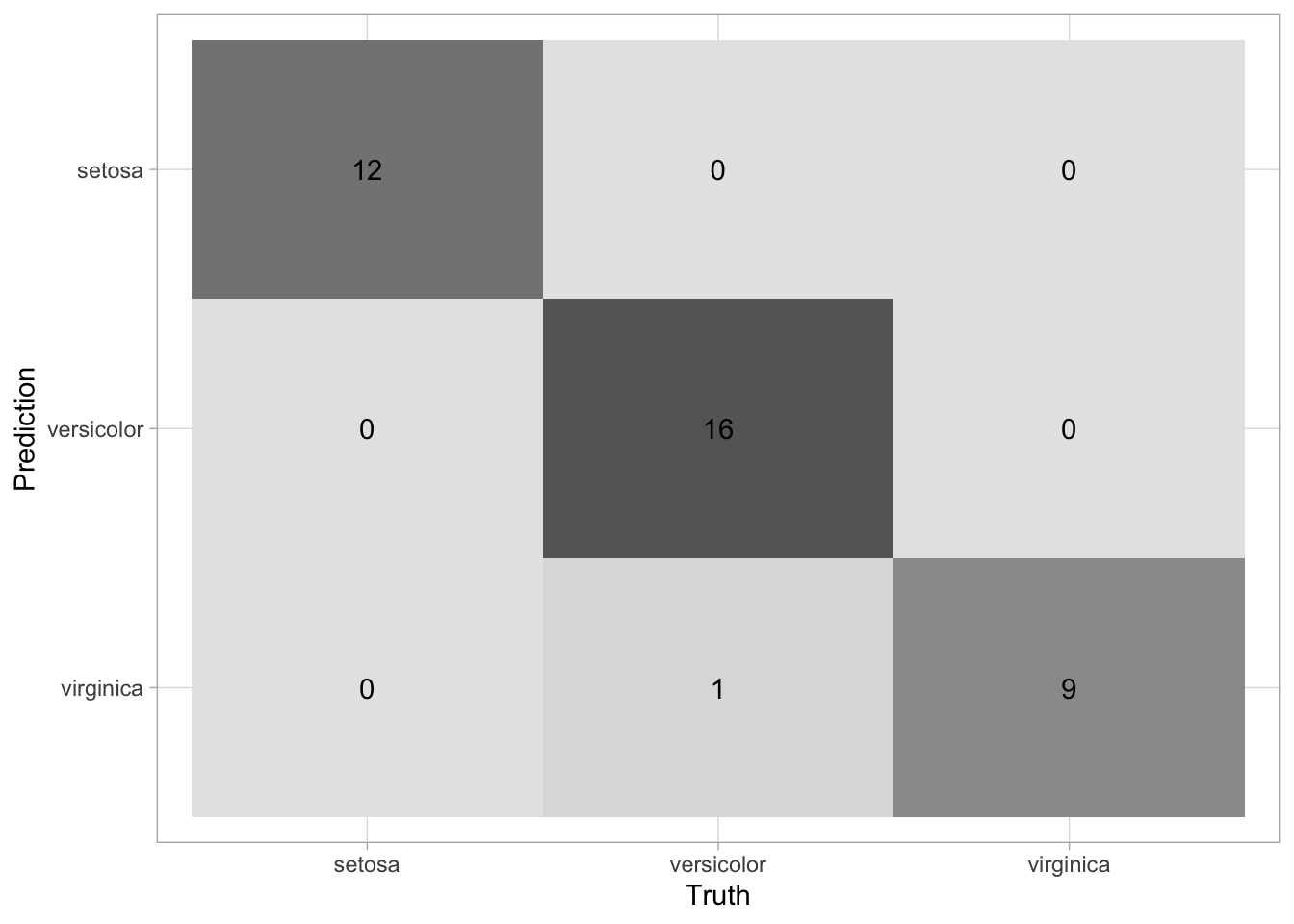
Final thoughts
Both models exhibit near perfect predictive power but are they really that good? From our visual analysis, we can confidently say that the combination of explanatory features provide for a clean separation of species. So yes, our toy model is that good!
Special thanks to Julia Silge, David Robinson and Andrew Couch for creating and sharing many amazing learning resources for mastering the tidyverse and tidymodels data science packages.
Gabriel Mednick, PhD
Data scientist, biochemist, computational biologist, educator, life enthusiast